Segmentando Clientes
Na MAPI empresa que trabalhei, tive a oportunidade de transitar em diversos atividades, começando por criar um produto para favorabilidade de empreedimentos residencial, tratamento de qualidade de dados, aprimoramento na captura de dados nos scripts de scraping. Por último estava no setor de marketing, criando um ebook da retrospectiva do mercado imobiliário em 2019. A área de marketing me interessou bastante, logo comecei a fazer os cursos da hubspot, para me aprimorar nas terminologias e funções.
No momento estou participando de discussões semanais dos notebooks no kaggle, selecionados por mais três amigos e colegas de profissão. Ao selectionar o notebook de análise de dados da olist me chamou atenção a prática de uma metodologia RFM para categorização de clientes.
O post tem o interesse de esclarecer a metodologia RFM para segmentação de clientes, uma revisão crítica sobre possibilidades estatísticas, funil de processos nas empresas, potenciais desdobramentos de análise.
Antes de mais nada, a olist conecta micro empreendedores de todo o Brasil para canais de vendas sem excesso de burocracia com apenas um único contrato. Esses vendedores estão habilitados para vender seus produtos por meio do Olist Store e entregar os produtos para os clientes usando os parceiros de logística do Olist. Para saber mais acesse o site
Os dados utilizados aqui no estudo, estão disponíveis no kaggle. Baixei todos os datasets disponiveís e importei para um sql local! As variáveis de cliente e vendedores estão representados por códigos por questões de sigilo. A base de dados contém informaçães de 100 mil pedidos entre 2016 e 2018 realizado por vários marketplaces no brasil. As características permitem analisar os pedidos em diversas camadas: Status do pedidos, preço, pagamento e performance do frete dado a localização do cliente. Os atributos de produto e as avaliaçãoes escritas pelos clientes.
Metodologia RFM
A metodologia RFM analisa o comportamento do cliente examinando por meio do histórico das transações, levando em consideração os seguintes critérios:
- Quão recente o cliente realizou a compra (Recency)
- Quão frequente o cliente compra (Frequency)
- Quanto o clientegastou (Monetary)
A metodologia ajuda a identificar clientes mais prováveis a responder promoções segmentado em diversas categorias. Essas categorias podem ser criadas de acordo com a regra de negócio da empresa.
O workflow de análise é precedido por coletar dados das transações do cliente. No caso do e-commerce é a realização da compra, sendo assim necessário:
- Dados: uma tabela com a identificação única dos clientes, com a informação da data da compra e o valor do produto.
- RFM tabela: é agregada a informação por cliente calculando a data da última compra, quantas compras foram feitas e o total gasto.
- RFM Score: Cada dimensão do RFM de cada cliente recebe um score de acordo com um critério intervalar adotado.
- Segmentos: A partir dos scores de cada dimensão é criado regras de negócios para caracterízação do cliente.
Dados
olist_clean %>% # Dataset estudo
head() %>%
kableExtra::kable(digits = 0)| customer_unique_id | order_date | revenue |
|---|---|---|
| 3818d81c6709e39d06b2738a8d3a2474 | 2018-01-14 | 199 |
| 107e6259485efac66428a56f10801f4f | 2018-03-24 | 60 |
| b32ff8caad5902c55fa167e7dc77cc69 | 2018-03-26 | 82 |
| fbe6316a06058c651539cbf59ec5a0ef | 2017-05-18 | 103 |
| fbe6316a06058c651539cbf59ec5a0ef | 2017-05-18 | 206 |
| 770c43f54c33cbf4bc49b7f2d6576891 | 2018-02-21 | 85 |
RFM tabela
Para calcular a diferença de dias da última transação do cliente é necessário definir uma data de referência. A data de referência que vou adotar é a data do cliente mais recente na base no caso 03/09/2018. O cálculo das métricas é bem simples, simplesmente a contagem de compras realizadas pelo cliente e total gasto nas compras.
date_analyse <- max(olist_clean$order_date); date_analyse## [1] "2018-09-03"rfm_table <-
rfm::rfm_table_order(data = olist_clean,
customer_id = customer_unique_id,
order_date = order_date,
revenue = revenue,
analysis_date = date_analyse)| customer_id | date_most_recent | recency_days | transaction_count |
|---|---|---|---|
| 0000366f3b9a7992bf8c76cfdf3221e2 | 2018-05-10 | 116 | 1 |
| 0000b849f77a49e4a4ce2b2a4ca5be3f | 2018-05-07 | 119 | 1 |
| 0000f46a3911fa3c0805444483337064 | 2017-03-10 | 542 | 1 |
| 0000f6ccb0745a6a4b88665a16c9f078 | 2017-10-12 | 326 | 1 |
| 0004aac84e0df4da2b147fca70cf8255 | 2017-11-14 | 293 | 1 |
| 0004bd2a26a76fe21f786e4fbd80607f | 2018-04-05 | 151 | 1 |
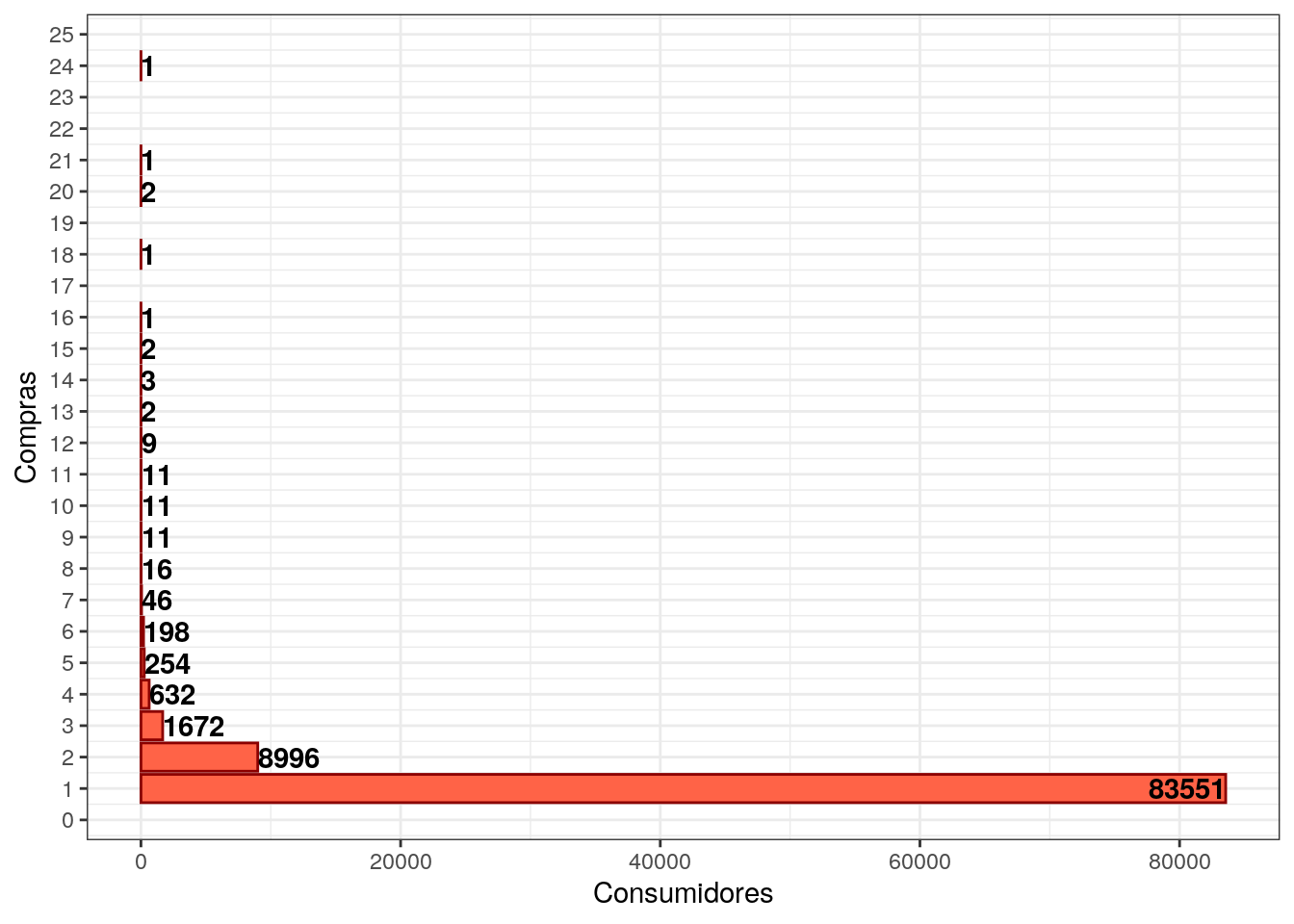
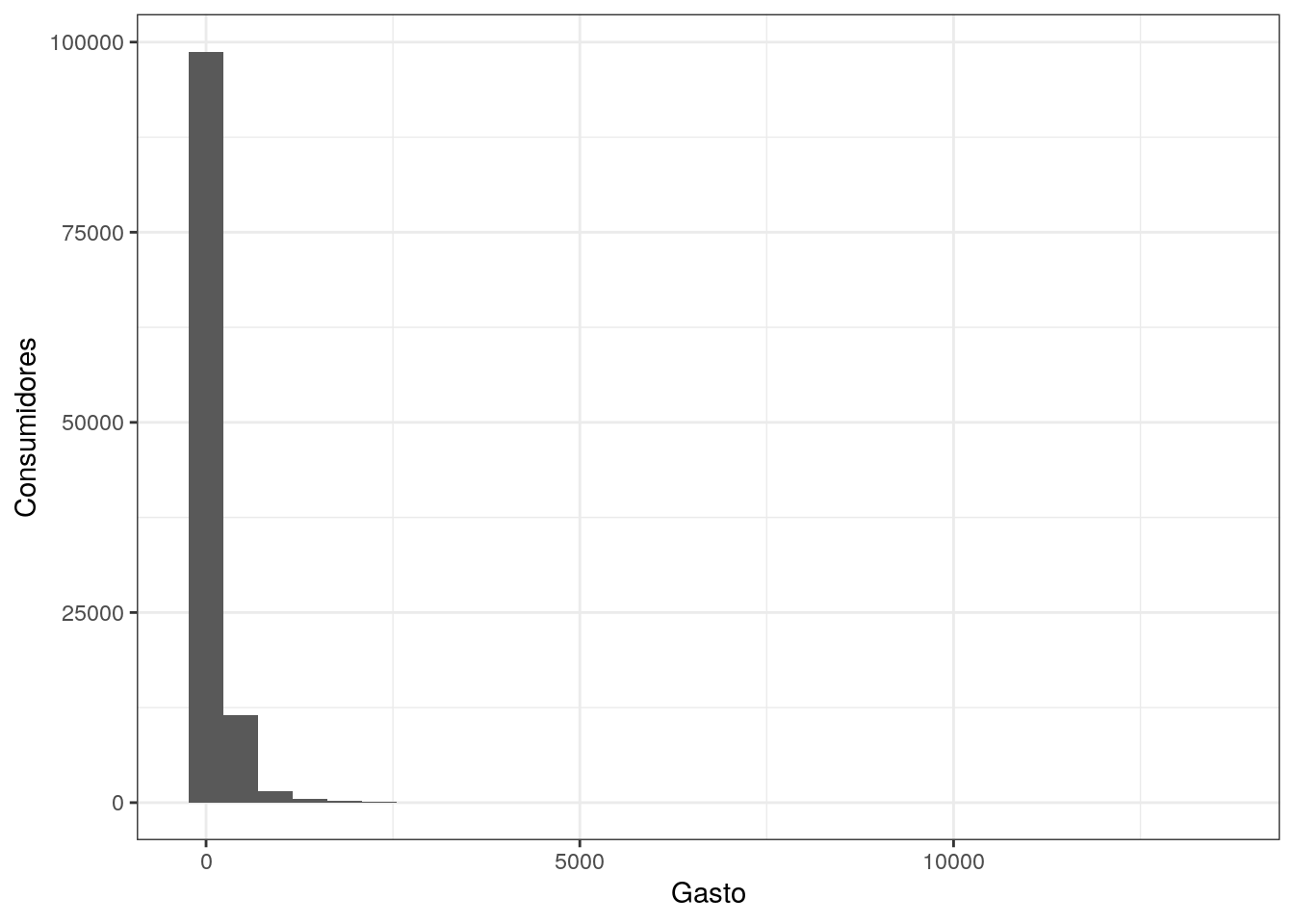
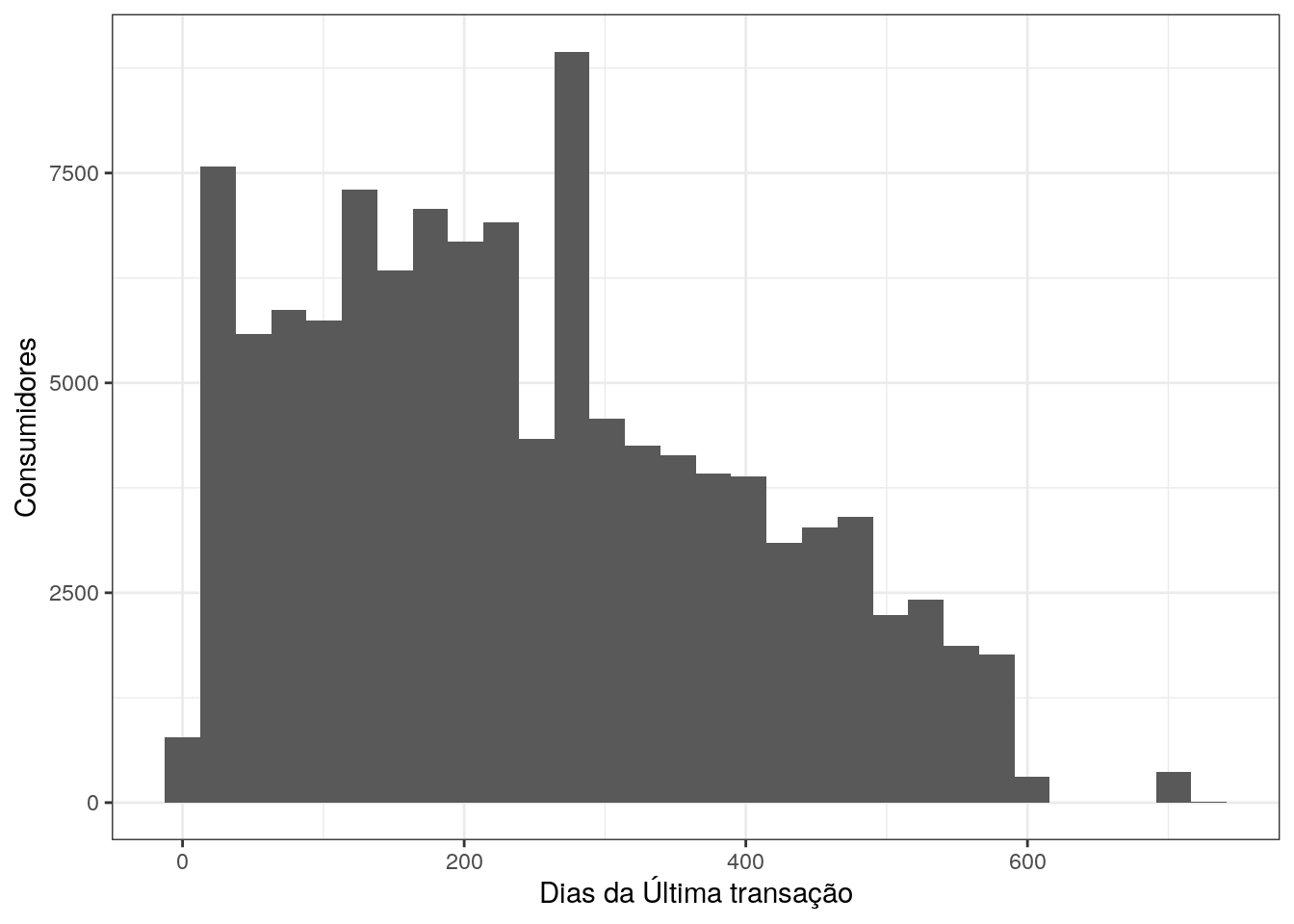
Explorando cada atributo dos indicadores, todos são bem assimétricos a direita, exceto a diferença de dias um pouco menos. A maioria dos clientes fez 1 compra, e houve a até clientes que realizou 24 compras. Cerca de 80% dos clientes gastaram até 174 reais. Em média o tempo da última compra foi realizada a 8
RFM SCORE
O score de cada atributo é definido pelo critério de bins. O score recebe um valor de 1 a frequency_bin. O bins é uma segmentação quantílica univariada, ou seja no caso, estamos compactando a variável na escala original para transformar em grupos de a 1 a 5.
rfm_score <-
rfm::rfm_table_order(data = olist_clean,
customer_id = customer_unique_id,
order_date = order_date,
revenue = revenue,
analysis_date = date_analyse,
frequency_bins = 5) # Definição de quantos grupos faremos| customer_id | recency_score | frequency_score | monetary_score | rfm_score |
|---|---|---|---|---|
| 0000366f3b9a7992bf8c76cfdf3221e2 | 4 | 1 | 4 | 414 |
| 0000b849f77a49e4a4ce2b2a4ca5be3f | 4 | 1 | 1 | 411 |
| 0000f46a3911fa3c0805444483337064 | 1 | 1 | 2 | 112 |
| 0000f6ccb0745a6a4b88665a16c9f078 | 2 | 1 | 1 | 211 |
| 0004aac84e0df4da2b147fca70cf8255 | 2 | 1 | 4 | 214 |
| 0004bd2a26a76fe21f786e4fbd80607f | 4 | 1 | 4 | 414 |
O resultado de cada um indicador é calculado por quantis univariados. Manualmente abaixo disponho da tabela que referencia os valores de acordo o grupo. Por se tratar de variáveis com interpretações diferentes, quanto mais recente a compra maior o peso do grupo, em contrapartida o valor e a frequência quanto maior melhor. A tabela referencia cada grupo de resultado para cada score, repare que o indicador de level_frequency só existem dois devido a dominância do grupo com 1 compra por cliente.
level_amount <- gtools::quantcut(rfm_score$rfm$amount, q = 5) %>% levels()
level_recency <- gtools::quantcut(rfm_score$rfm$recency_days, q = 5) %>% levels() %>% rev()
level_frequency <- gtools::quantcut(rfm_score$rfm$transaction_count, q = 5) %>% levels()| level_amount | level_recency | level_frequency | grupo_rfm_score |
|---|---|---|---|
| [0.85,39.9] | (389,729] | 1 | 1 |
| (39.9,69.9] | (273,389] | 2 | |
| (69.9,115] | (182,273] | 3 | |
| (115,197] | (98,182] | 4 | |
| (197,6.05e+04] | [0,98] | (1,24] | 5 |
O score no final das contas é baseado na seguinte cálculo:
RFM Score = recency_score * 100 + frequency_score * 10 + monetary_score
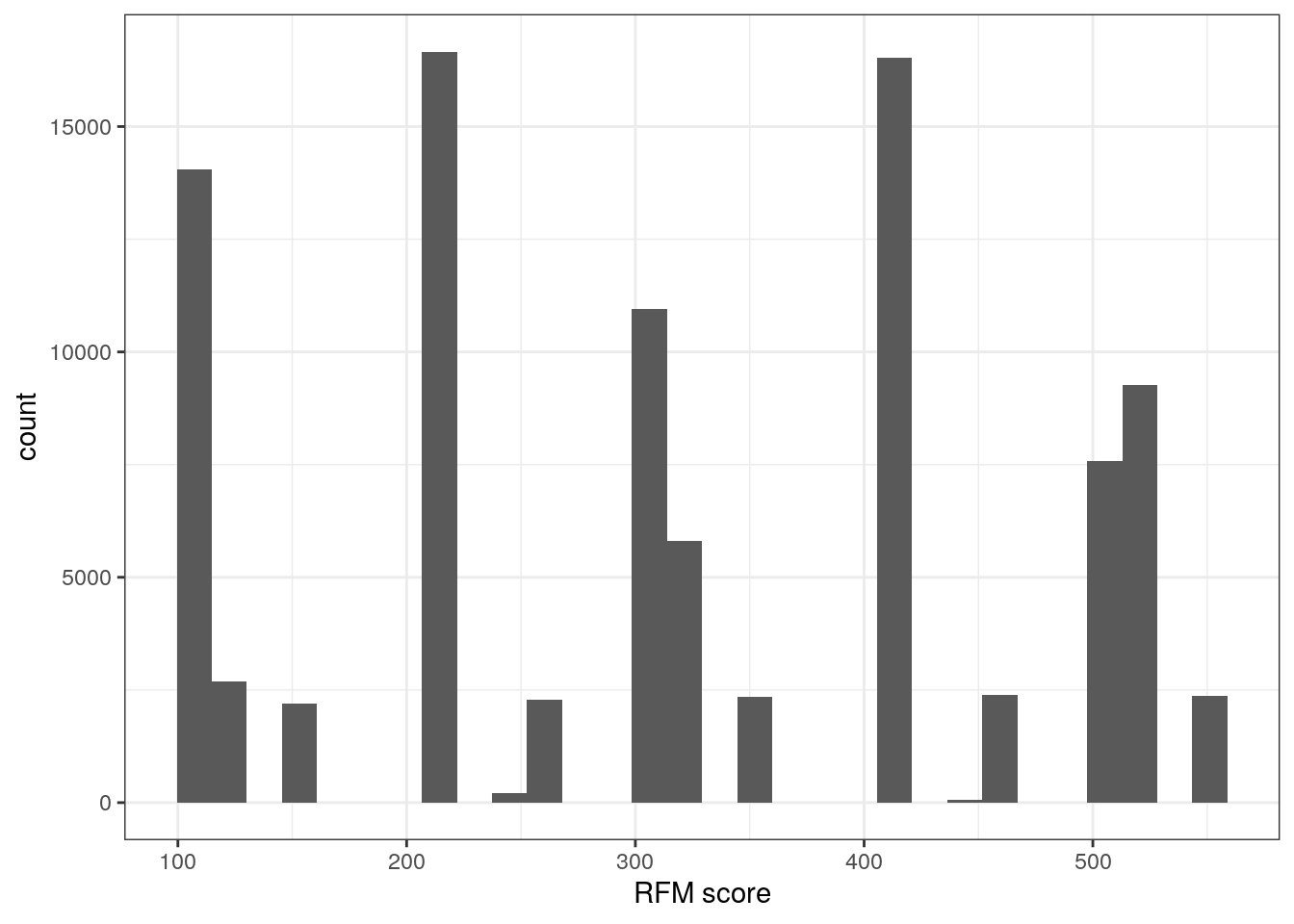
Tratar o resultado do score como contínuo não é recomendado pois o score é uma variável com valores pré-definidos pela quantidade de bins. Pelo histograma essa ideia fica mais nítida, o score não é continuamente presente entre 111 a 555. Repare nos espaços em branco entre as barras.
Segmentos
Dessa forma, estamos interessados em rotular os resultados de acordos os scores, esta parte do método torna flexível para criar regras de negócio de acordo com a corporação. No caso vou utilizar os rótulos da vinheta do pacote rfm, apenas traduzi os segmentos.
rfm_set <- priori_rfm() # Função que envelopa
rfm_set$table_segments %>%
knitr::kable(align = "c")| Segment | Description | R | F | M |
|---|---|---|---|---|
| Campeão | Compra recentemente, compra frequentemente e gasta muito | 4 - 5 | 4 - 5 | 4 - 5 |
| Consumidor Leal | Gasta uma quantidade rasoável. Resposível para promoções | 2 - 5 | 3 - 5 | 3 - 5 |
| Potencial Leal | Cliente recente, Gasta uma quantidade razoável, compra mais de uma vez | 3 - 5 | 1 - 3 | 1 - 3 |
| Novos clientes | Comprou mais recentemente, mas não frequentemente | 4 - 5 | <= 1 | <= 1 |
| Promissor | Compra recente, mas não gasta muito | 3 - 4 | <= 1 | <= 1 |
| Precisa de Atenção | Acima da média em compras recentes, frequentes e valor | 2 - 3 | 2 - 3 | 2 - 3 |
| Prestes a hibernar | Abaixo da média, em compras recentes, frequentes e valor | 2 - 3 | <= 2 | <= 2 |
| Em risco | Gasta um bom dinheiro, compra frequentemente mas faz tempo que comprou | <= 2 | 2 - 5 | 2 - 5 |
| Não pode perder | Gasta muito dinheiro, compra frequentemente mas faz um bom tempo que comprou | <= 1 | 4 - 5 | 4 - 5 |
| Perdido | Gastam poucos, pouca frequência, e faz tempo que não compra | 1 - 2 | 1 - 2 | 1 - 2 |
segments_olist <-
rfm::rfm_segment(
rfm_score,
rfm_set$segment,
rfm_set$recency_lower, rfm_set$recency_upper,
rfm_set$frequency_lower, rfm_set$frequency_upper,
rfm_set$monetary_lower, rfm_set$monetary_upper)Ao considerar a segmentação dos grupos, não há validade na classificação do Precisa de Atenção e Prestes a Hibernar, pois univariadamente a distribuição dos indicadores não possuem uma distribuição simétrica. OS dois gráficos abaixo relacionam a quantidade de clientes em cada grupo. Os grupos de lealdade e inatividade podem ser usados para comparação da jornada do cliente, para que possa explicar os motivos dos clientes perdidos. Curiosamente não há nenhum cliente como campeão, muito em função porque os dados que usei são de temáticas diferentes e consequetemente tem necessidades de compras e preços diferentes.
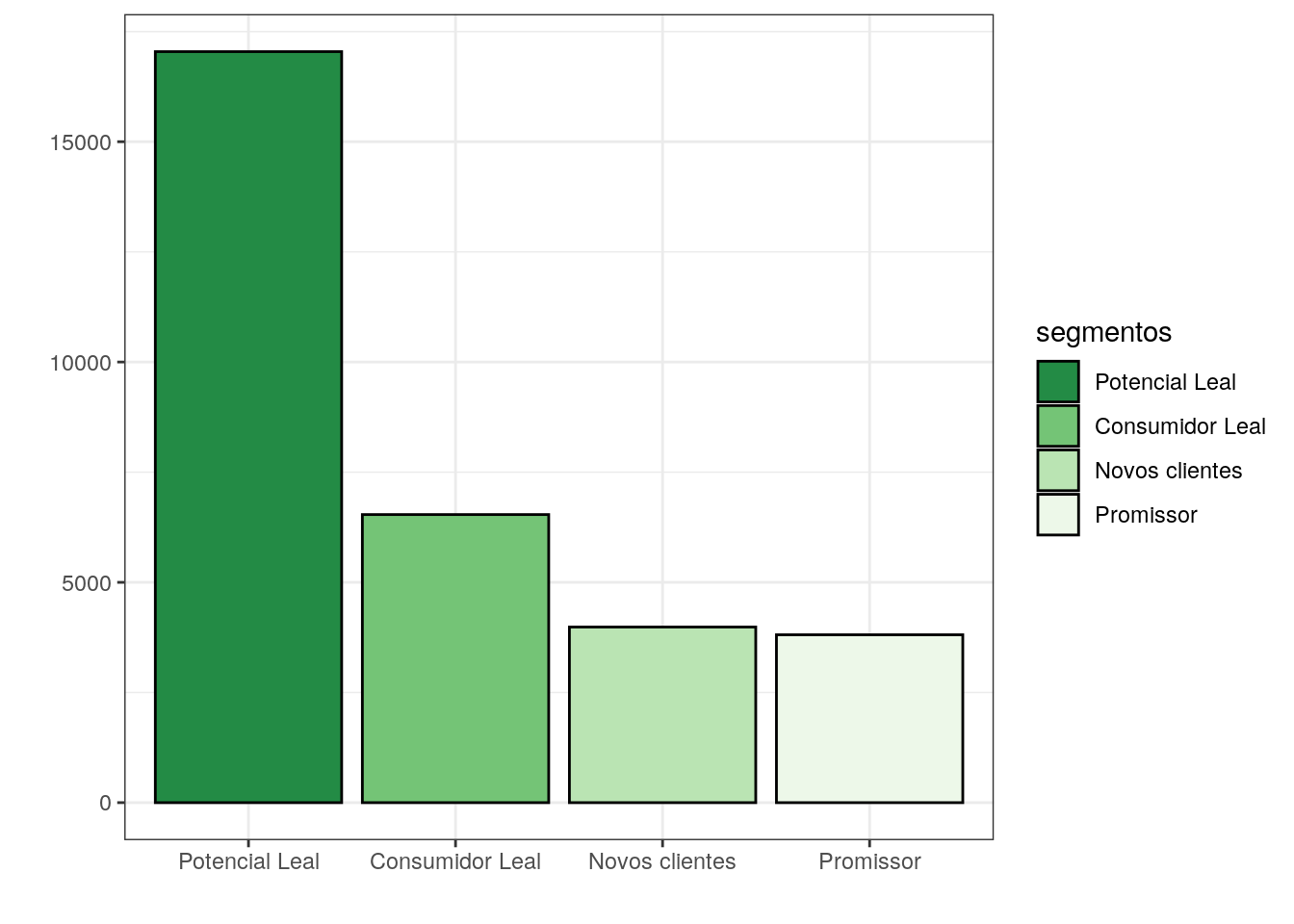
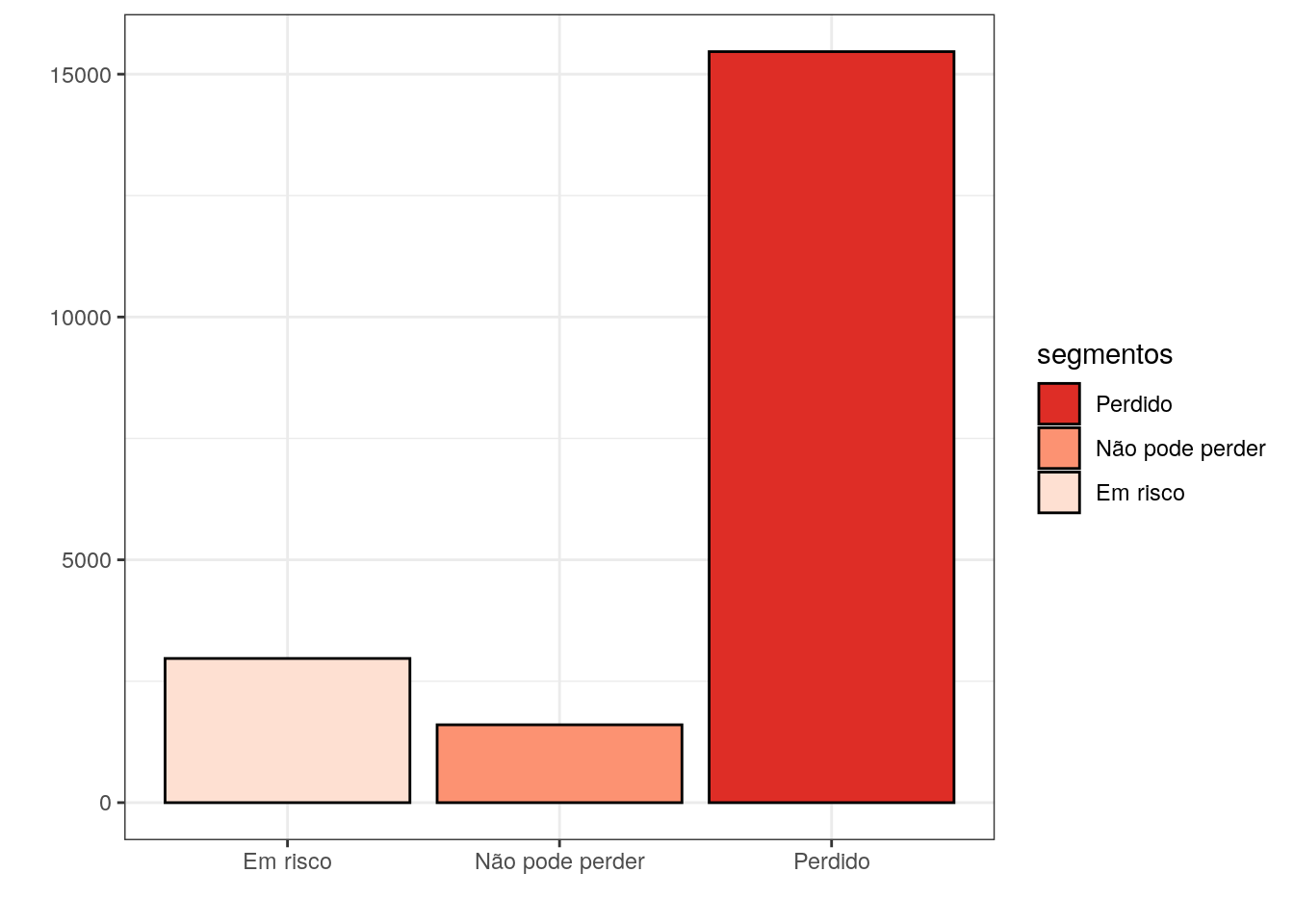
Além de disso podemos usar a informação para avaliar o tratamento que cada empresa tem sob o cliente ou o quanto se preocupa. Agora é uma análise inversa:
| customer_id | seller_id | segment |
|---|---|---|
| de44ecdecadfbd5d7c4943889af1c915 | fc906263ca5083d09dce42fe02247800 | Lost |
| 40f3ad678e7faf0682800ca130302eb9 | fc906263ca5083d09dce42fe02247800 | Lost |
| 6ce08c3a8b69a46f5bd4f0acd2fa75da | fc906263ca5083d09dce42fe02247800 | Lost |
| c8c4e5f83e41a1c32b287793785cf3f7 | fc906263ca5083d09dce42fe02247800 | Lost |
| 6b9b119304bd30a72e528d9288127022 | fc906263ca5083d09dce42fe02247800 | Lost |
| f5de50704f1a1c6df7f9c6912c9a3678 | fc906263ca5083d09dce42fe02247800 | Lost |
Apresento a seguir a lista de empresa que mais foi rotulada com clientes perdidos proporcionalmente.
| seller_id | segment | perc | n_seller |
|---|---|---|---|
| fc906263ca5083d09dce42fe02247800 | Lost | 84.87395 | 119 |
| f4aba7c0bca51484c30ab7bdc34bcdd1 | Lost | 82.05128 | 117 |
| 3504c0cb71d7fa48d967e0e4c94d59d9 | Lost | 81.13208 | 53 |
| cce6ab8d1682639fe45ab70234f1665f | Lost | 78.78788 | 66 |
| 9616352088dcf83a7c06637f4ebf1c80 | Lost | 68.36735 | 98 |
| 827f8f69dfa529c561901c4f2e0f332f | Lost | 67.30769 | 104 |
Das 116 compras realizadas na empresa fc906263ca5083d09dce42fe02247800 84 % dos clientes dificilmente vão retornar a comprar, quase 100 clientes dos 119 que compraram.
O resultado do rfm por empresa pode ser um novo serviço da olist: enviar qual o posicionamento da empresa perante os clientes dado a concorrência, ou seja quais empresas precisam rever ou se capacitar para o tratamento e acompanhamento do cliente. Por outro lado, a empresa que vende seus produtos no e-commerce poderia usar a segmentação do rfm para realizar testes a/b estraficada, com promoções, avisos de produtos. A segmentação dos grupos também poderia ser usada como fator de explicação, para o grau de dificuldade da jornada do cliente ou tempo de frente.
Resumo
A metodologia rfm é uma análise rápida e simples do comportamento dos clientes. O score não possue muita validade, mas sim as classificações de acordo com a regra de negócio da empresa, porém é necessário tomar cuidado com as descrições de cada grupo, pois no caso Prestes a hibernar e Precisa de Atenção não possuem validade, já que as distribuições dos indicadores são assimétricas. Como melhoria de análise seria melhor realizar o rfm para cada temática de produto, não ficando refem a valores extremos. Como resultado, é possível avaliar o cliente nas diversas categorias de produto e saber as suas preferências. Por fim, é de total estratégia realizar métricas períódicas com esta metodologia para acompanhamento de clientes na empresa.