Vinheta elasticR
Vinheta são documentações de casos de uso de pacotes do R. Os pacotes do R, que geralmente estão CRAN utilizam desse artifício para explicar as principais funcionalidade do pacote.
Na MAPI, empresa que trabalhava do ramo de ciência de dados para o mercado imobiliário, extraímos anúncios de imóveis em portal e imobiliárias de Curitiba e no estado de São Paulo. A partir desses dados transformavamos em informação criando produtos para o segmento de incorporação nas métricas de exclusividade, precificação e valorização do empreendimento. Esse produto era parte da empresa e pode ser encontrado na Isket.
Entretanto para acessar esses dados, estavam disponível no ElasticSearch. Confesso que quando entrei nunca tinha trabalho com essa estrutura de dados, também considerados NOSQL e no caso a query a ser feita era bem mais complexa. Nós usamos elasticsearch devido a agilidade na busca dos filtros da plataforma Loopim, produto para corretor de imóvel e imobiliária.
Os pacotes existentes no R elasticsearchr e elastic, não obitve êxito. Sendo assim, decidimos criar nossas próprias funções de extração de dados por meio de uma requisição GET. O pacote é elasticR no qual envelopa as principais query utilizadas. A intenção do conteúdo é expor todas as funções e claro contar com a sua contribuição para melhorar o pacote.
Instalação do Pacote:
devtools::install_github("gabrielsartori/elasticR")
require(elasticR)Para usar praticamente todas as funções é necessário carregar os pacotes dplyr, purrr e sf. Na vinheta, apresento o resultado das querys espaciais em mapa, sendo assim carrego os pacotes ggplot2 e magrittr para manipulação de dados.
require(dplyr)
require(purrr)
require(sf)
require(ggplot2)
require(magrittr)Todas as funções começas com es.*. A primeira situação é extrair quais as variáveis existentes na tabela de interesse. Neste exemplo de vamos trabalhar com a tabela “realties” que são informações dos anúncios de imóveis vigentes.
elasticR::es.variable(
user = "nome_usuário",
passwd = "senha",
find_search = "search", # Geralmente search
database = "nome_base_de_dados", # nome do banco de dados
table = "realties" # nome da tabela
)O resultado mostra um vetor de caracteres dos nomes das variáveis. Apresento a seguir algumas das variáveis presentes na base de dados.
## [1] "finalidade" "latitude" "longitude" "opcionais" "tipo_negocio"
## [6] "valor"Além de saber os nomes das variáveis presentes, é importante saber qual a tipagem da variável. O elasticsearch como veremos logo a seguir tem características particulares.
type_variable <-
elasticR::es.variable.type(
user = "nome_usuário",
passwd = "senha",
find_search = "search", # Geralmente search
database = "nome_base_de_dados", # nome do banco de dados
table = "realties"
)O retorno da type variable é uma lista nomeada com três categorias. list_variable retorna uma lista de variáveis com as respectivas variáveis que fazem parte e as tipagens. No caso, os opcionais retornam três colunas presentes na lista. Repare que location e name tratam do tipo keyword, é um atributo do tipo texto, que somente são filtradas pelor valor exato do campo. Caso queira mais detalhes acesse a nota do elasticsearch.
type_variable %>%
names()## [1] "list_variable" "univariate_variable" "raw_variables"type_variable %>%
.$list_variable %>%
.$opcionais## # A tibble: 1 x 3
## category location name
## <chr> <chr> <chr>
## 1 text keyword keywordJá univariate_variable retorna diretamente a tipagem do campo existente. No exemplo, temos valor, latitude e longitude como campos numéricos, já tipo negócio e finalidade como texto. A relação completa das tipagem de variáveis e comparando com o padrão do SQL está dispónível aqui.
type_variable %>%
.$univariate_variable %>%
select(c("valor", "tipo_negocio", "finalidade", "latitude", "longitude")) %>%
knitr::kable(align = "c") %>%
kableExtra::kable_styling(position = "center")| valor | tipo_negocio | finalidade | latitude | longitude |
|---|---|---|---|---|
| float | text | keyword | float | float |
A raw_variable são as variáveis que quando for usada para agregações é necessário colocar .raw depois da variável. Caso queira mais detalhes acesse a nota do elasticsearch.
type_variable %>%
.$raw_variables ## [1] "default" "descricao" "tipo_imovel" "tipo_negocio"Acessando a tabela de dados
Toda e qualquer função é necessário passar as credencias. A credencial nada mais é que o caminho da requisição no caso, reforçando vamos trabalhar com dados de imóveis. A função recebe os mesmos parâmetros de es.variable e es.variable.type.
credential_realties <-
elasticR::es.credential(
user = "nome_usuário",
passwd = "senha",
find_search = "search",
database = "nome_base_de_dados",
table = "realties"
)Para pegar todas as colunas, mas com restrição nas linhas utilize a função es.alldata. Todo query por padrão no elasticsearch retorna 10 resultados, em todas as funções é possível aumentar a quantidade de dados.
realties <-
elasticR::es.alldata(
credential = credential_realties,
size = 100
)realties %>%
select(c("valor", "tipo_negocio", "finalidade", "latitude", "longitude")) %>%
nrow()## [1] 100realties %>%
select(c("valor", "tipo_negocio", "finalidade", "latitude", "longitude")) %>%
head()## valor tipo_negocio finalidade latitude longitude
## 1 650000 Venda Residencial NA NA
## 2 620000 Venda Rural NA NA
## 3 2128000 Venda Residencial NA NA
## 4 1300000 Venda Residencial NA NA
## 5 750000 Venda Residencial NA NA
## 6 1600000 Venda Residencial NA NAPara pré-selecionar antes as variáveis utilize a função e com restrição nas linhas utilize es.columndata.
realties_var <-
elasticR::es.columndata(
credential = credential_realties,
size = 100,
variable = c("valor", "tipo_negocio", "finalidade", "latitude", "longitude"))realties_var %>%
nrow()## [1] 100realties_var %>%
head()## tipo_negocio finalidade valor latitude longitude
## 1 Venda Residencial 650000 NA NA
## 2 Venda Rural 620000 NA NA
## 3 Venda Residencial 2128000 NA NA
## 4 Venda Residencial 1300000 NA NA
## 5 Venda Residencial 750000 NA NA
## 6 Venda Residencial 1600000 NA NAFiltrando os dados
Para extrair os dados com filtros de resposta há duas funções a es.filterun que somente trabalha com um único filtro e uma única resposta. A função es.filtermult é possível indicar mais filtros e com resposta múltiplas. Os filtros acrescidos, funcionam como operadores (&,e) ou seja, ainda não é possível colocar no filtro a situação um ou outro.
realties_rural <-
elasticR::es.filterun(
credential = credential_realties,
variable = c("valor", "tipo_negocio", "finalidade", "latitude", "longitude"),
size = 100,
filter = "finalidade",
answer = "Rural"
)realties_rural %>%
select(finalidade) %>%
table()## .
## Rural
## 100Na próxima faremos uso do .raw, vamos fazer uma query filtrando pelo tipo negócio e o bairro. O bairro é uma variável lista, para acessar o nome deve ser especificado neste formato: bairro.nome. Segue abaixo a aggregação da contagem de cada variável.
realties_cwb_centro_cristo_rei <-
elasticR::es.filtermult(
credential = credential_realties,
variable = c("cidade_uf", "quarto", "valor", "tipo_negocio", "finalidade", "bairro.nome"),
size = 1000,
es_filter =
list(
"finalidade" = "Comercial",
"cidade_uf" = "curitiba_pr",
"quarto" = "1",
"tipo_negocio.raw" = "Locação",
"bairro.nome.raw" = c("Centro", "Cristo Rei")
)
)## $tipo_negocio
##
## Locação
## 101
##
## $quarto
##
## 1
## 101
##
## $cidade_uf
##
## curitiba_pr
## 101
##
## $finalidade
##
## Comercial
## 101
##
## $bairro
##
## Centro Cristo Rei
## 93 8Agregação
Uma das facilidade em trabalhar com ferramentas deste banco de dados é usar a performance de agregações que são estatísticas sumarisadas. No caso há duas funções, es.catcount e es.summary. A primeira, conta a quantidade de informação na variável selecionada, use somente para variáveis do tipo texto e keywords. No exemplo, o tipo imóvel apartamento predomina na base de dados.
elasticR::es.catcount(
credential = credential_realties,
variable = "tipo_imovel.raw",
size = 3) tipo_imovel_count| tipo_imovel.raw | count |
|---|---|
| Apartamento | 3238649 |
| Casa | 1458577 |
| Terreno | 443701 |
A próxima função usa-se para variáveis numéricas, retorna medidas descritivas(mínimo, máximo, média) e os percentis. É possível também amplificar seu potencial usando a função map_dfr passando várias variáveis para serem sumarisadas.
elasticR::es.summary(
credential = credential_realties,
variable = "valor") %>%
knitr::kable(align = "c")| variable | pct_1 | pct_5 | pct_25 | pct_50 | pct_75 | pct_95 | pct_99 | count | min | max | avg | sum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| valor | 738.3736 | 1600.013 | 218362.3 | 410000.9 | 799998.4 | 2501151 | 6505320 | 6136693 | 0 | 1.45e+09 | 804225.4 | 4.935284e+12 |
quarto_banheiro_summarise <-
purrr::map_dfr(
.x = c("banheiro", "quarto"),
.f = ~elasticR::es.summary(
credential = credential_realties,
variable = .x)
)| variable | pct_1 | pct_5 | pct_25 | pct_50 | pct_75 | pct_95 | pct_99 | count | min | max | avg | sum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| banheiro | 0 | 1 | 1 | 2 | 3 | 5 | 7 | 2327336 | 0 | 45 | 2.275807 | 5296568 |
| quarto | 0 | 1 | 2 | 3 | 3 | 4 | 5 | 5194647 | 0 | 60 | 2.525473 | 13118943 |
Por enquanto, não é ainda possível adicionar filtros nas querys de agregações.
Query Espaciais
Uma vantagem de ter um banco de dados no elasticsearch é realizar consultas com filtros geográficos. Os tipos permitidos está disponíveis na documentação. As funções aqui criadas, farão uso da localização da academia studio fit, para encontrar anúncios de até 1km.
# Lat/long academia
academia <- ggmap::geocode("Av. São José, 991 - Cristo Rei, Curitiba - PR, 80050-350")
imovel_academia <-
elasticR::es.buffer(
credential = credential_realties,
variable = c("valor", "tipo_negocio", "finalidade", "tipo_imovel", "quarto", "latitude", "longitude"),
latitude = academia$lat,
longitude = academia$lon,
size = 10000,
buffer = "1km"
)Realizando filtros, queremos só imóveis com a locação do tipo apartamento residencial e de 1 quarto.
locacao_ap_residencial <-
imovel_academia %>%
filter(finalidade == "Residencial",
tipo_imovel == "Apartamento",
tipo_negocio == "Locação",
quarto == 1)Manipulando as características geográficas da academia e dos anúncios temos o mapa que representa os dados extraídos.
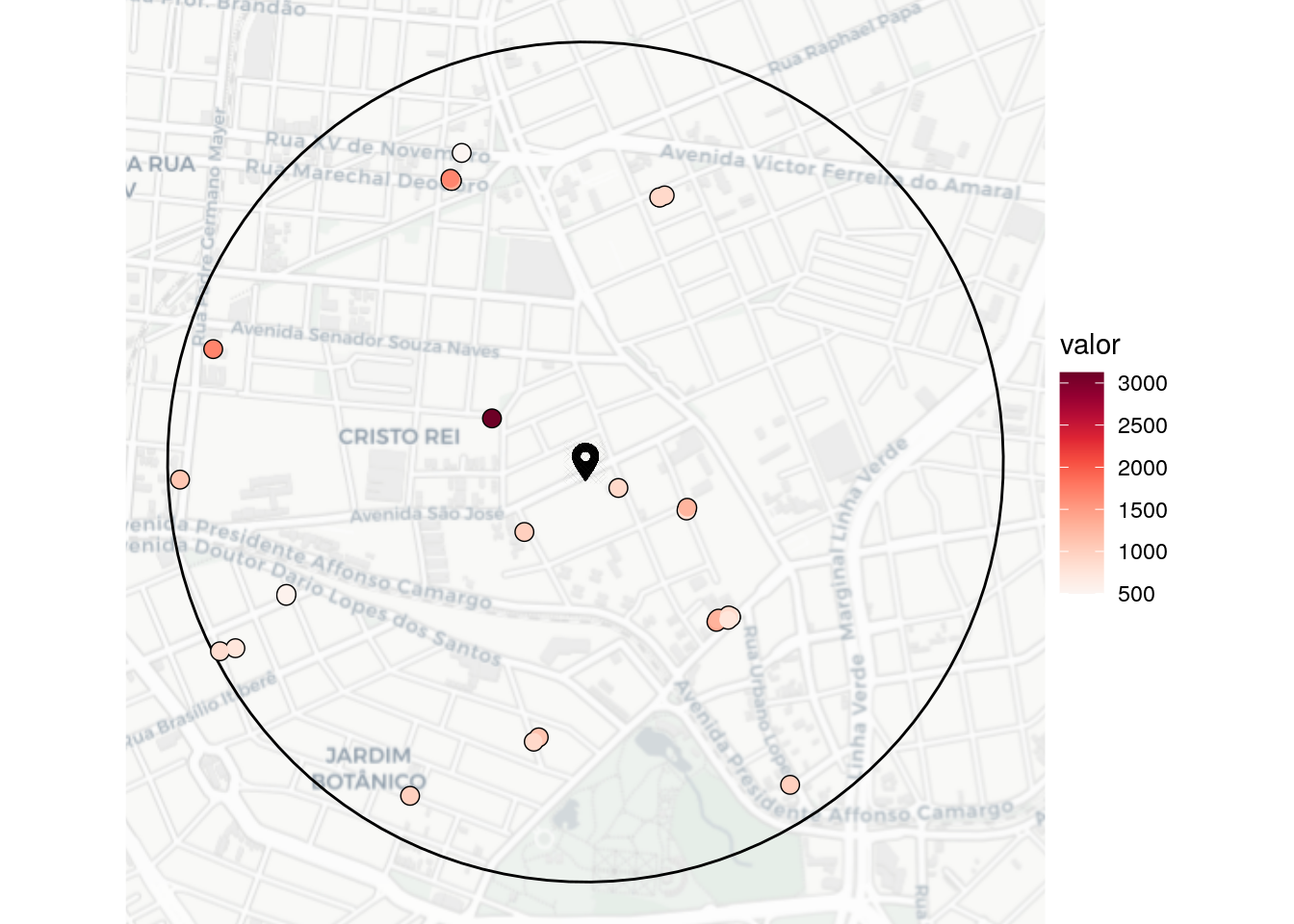
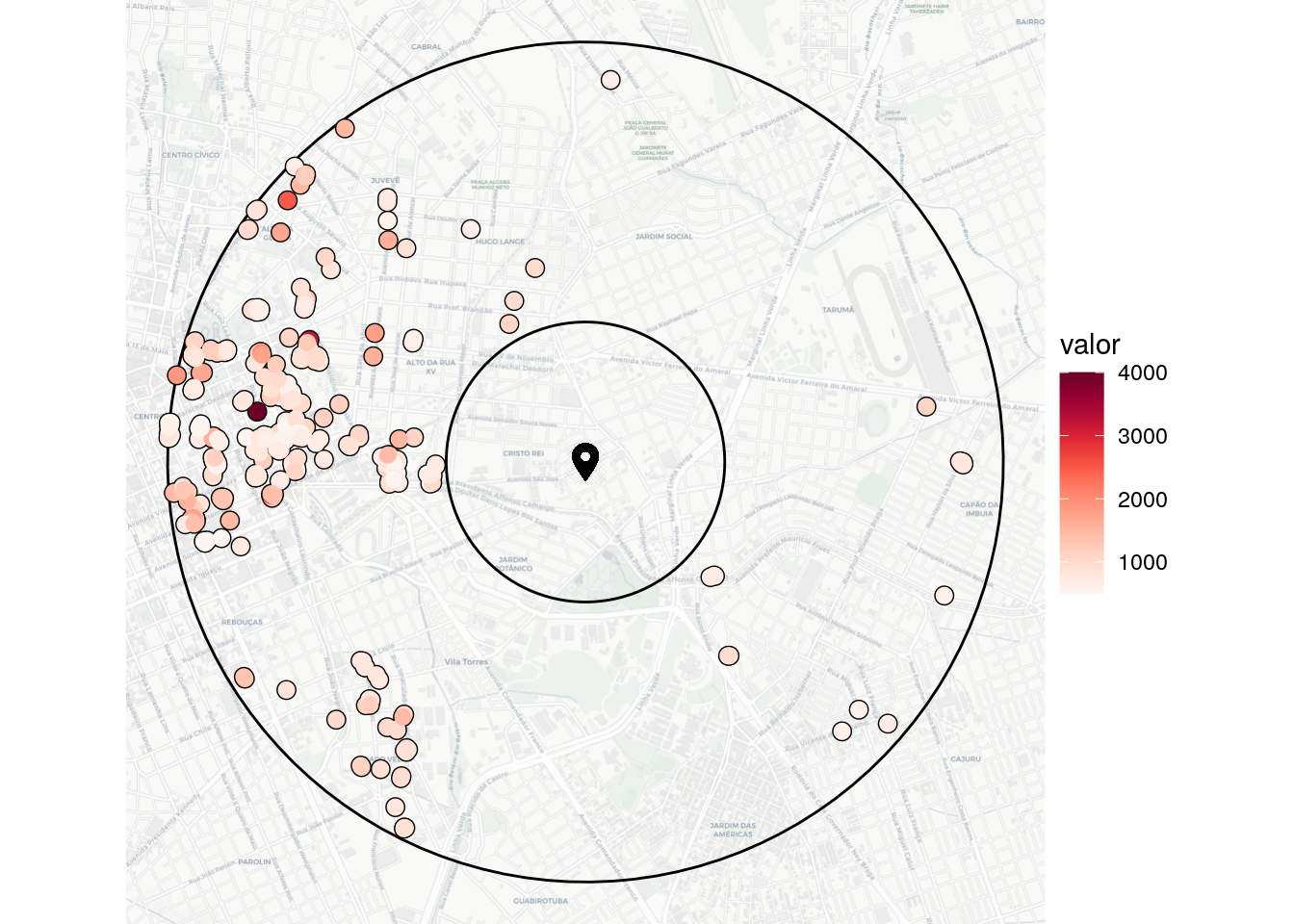
Outra situação é encontrar imóvel entre duas faixas geográficas em um raio. Na função es.buffer.ring extraimos dados entre dois raios geográficos. Realizando os mesmos filtros de anúncios e exploramos o mapa a seguir.
academia_1km_3km <-
elasticR::es.buffer.ring(
credential = credential_realties,
variable = c("valor", "tipo_negocio", "finalidade", "tipo_imovel", "quarto", "latitude", "longitude"),
latitude = academia$lat,
longitude = academia$lon,
size = 10000,
buffer = "1km",
ring = "3km"
)
A primeira versão do pacote é essa! Há muitas outras implentações que podem contribuir como filtros nas agregações e extrações de dados espaciais. Adicionar paginações, já que o elastic, limita a quantidade de dados geralmente 10.000 na configuração padrão a serem extraídos por cada query. Caso queira contribuir fique à vontade.