Existe Influência do Gênero no Salário?
Introdução
O site Data Hackers é um baita comunidade dos profissionais e estudantes que colaboram para a comunidade de ciencia de dados.
Desde 2018 quando foi criado o grupo do slack vem contribuindo com conteúdo para toda a comunidade.
Hoje em dias estão disponíveis em mais veículos comunitivos como: Youtube, Medium e Spotify.
Um das propostas para incentivar a comunidade é a realização da pesquisa State of Data: “Um mapeamento completo do cenário atual da área de dados do Brasil”
São informação sobre Demografia, Carreira, desafios de gestores, conhecimentos na área de dados e de cada profissão.
A pesquisa foi realizada em 2019, 2021 e 2022 (8 de Fevereiro Sai).
Ao mesmo tempo que permite a comunidade em conhecer as suas própria característica, cria desafios de dados
para fomentar as perspectivas e desenvolvimento dos profissionais e empresas.
Nesse estudo vou utilizar a pesquisa de de 2021 !
Referência
Como referência do estudo de interesse, utilizarei um dos notebooks vencedores, que ficaram no top 3 análises, disponível no Notebook Kaggle. A intenção é realizar outra abordagem para responder a seguinte pergunta: O gênero afeta o salário? As mais importantes alterações são:
3 modelos para cada profissão: cientista, analista e engenheiro
A técnica do modelo é logístico ordinal
A variável de gênero será a última no modelo
Dados
Da mesma forma para todas as análises serão feitos filtros e adequações a variáveis. Destaco as Seguintes:
p1_b_genero != "Outro"
& p2_a_qual_sua_situacao_atual_de_trabalho_nd != "Prefiro não informar"
Além de filtrar o banco é necessário identicar cada variáveis corresponente a profissão. O Banco de Dados indica cada conjunto de variável. Serão considerados no modelo as rotinas e domínio de linguagem de cada profissão assim como variáveis em comum: experiencia, cargo, formação.
Ao realizar esse filtro temos:
| p4_a_atuacao | df_nrow | df_col |
|---|---|---|
| Engenharia de Dados | 401 | 110 |
| Ciência de Dados | 410 | 119 |
| Análise de Dados | 847 | 116 |
Como são mais de 100 variáveis potenciais para colocar no modelo será realizado um filtro de variabilidade e significância via qui quadrado.
O filtro de variabilidade, a intenção é remover variáveis que são praticamentes únicas. Se uma variável não altera logo não contribui para o modelo. e a grande chance de ocorrer em variáveis dicotômicas (0 ou 1). Como ponto de corte, farei um filtro de representação entre 2.5 % e 97.5%.
A Variável Domínio de scala tem essa proporção em engenharia de Dados. Será mantida no modelo.
##
## 0 1
## 85.03937 14.96063A Variável Domínio de .Net tem essa proporção em engenharia de Dados. Será descartada no modelo
##
## 0 1
## 97.506234 2.493766O filtro Qui Quadrado, consiste no teste de hipótese de verificar associação entre a variável resposta com as explicativas. Ao aplicar o teste e remover as linhas com NA temos o seguinte desfecho:
| p4_a_atuacao | df_nrow | df_col |
|---|---|---|
| Engenharia de Dados | 381 | 27 |
| Ciência de Dados | 399 | 38 |
| Análise de Dados | 818 | 39 |
Estatística Descritiva
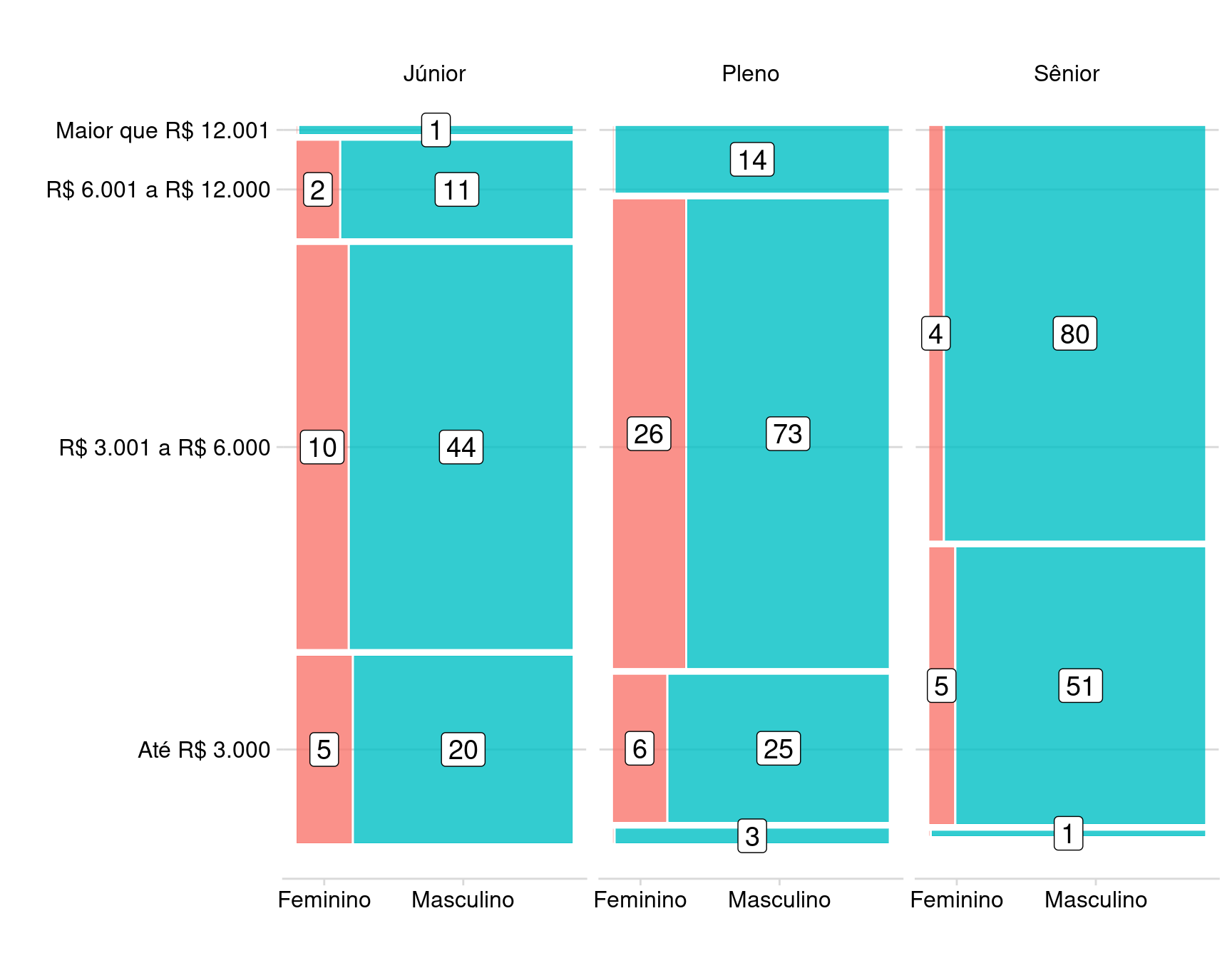
Mosaico Engenharia de Dados
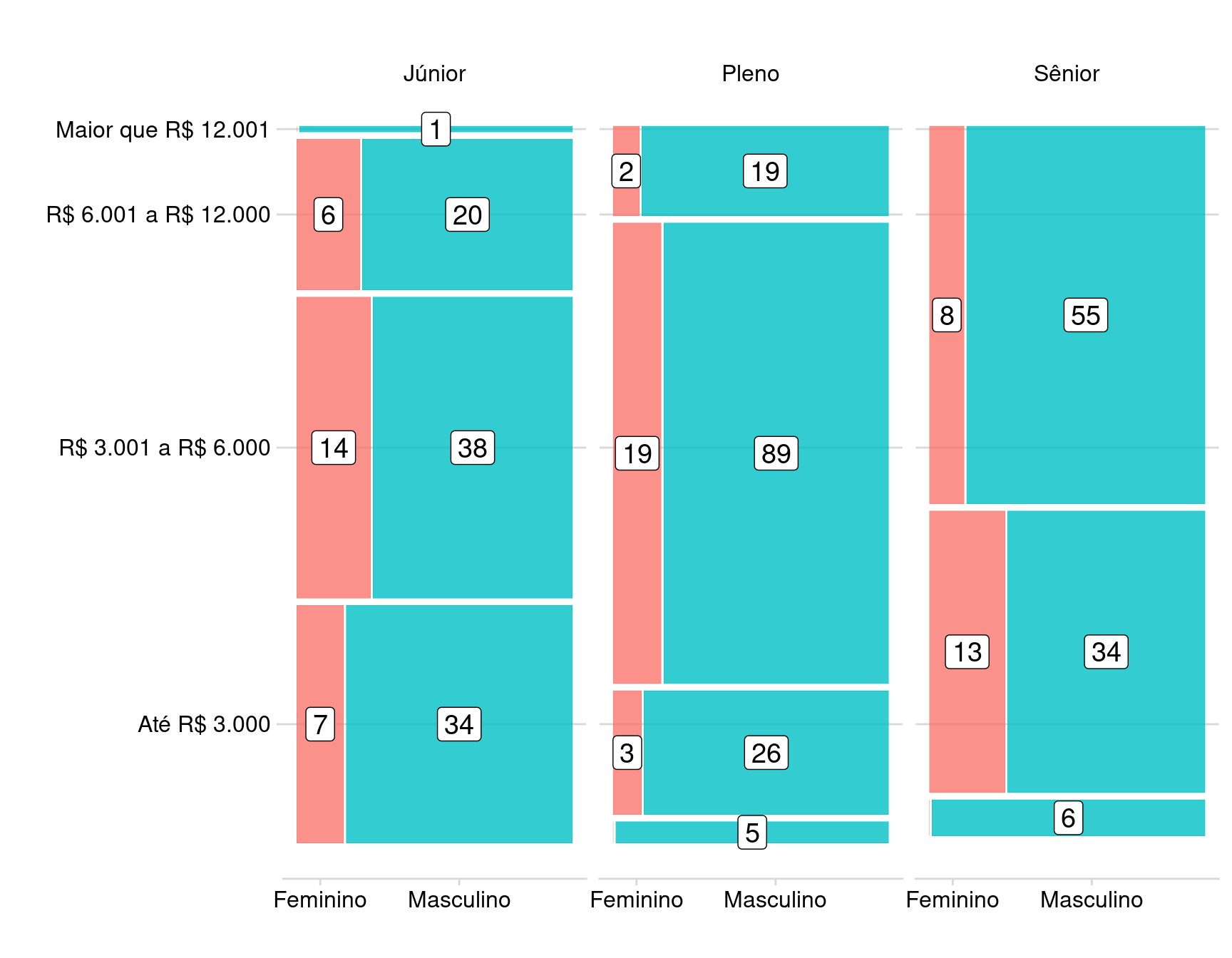
Mosaico Ciência de Dados
Mosaico Análise de Dados
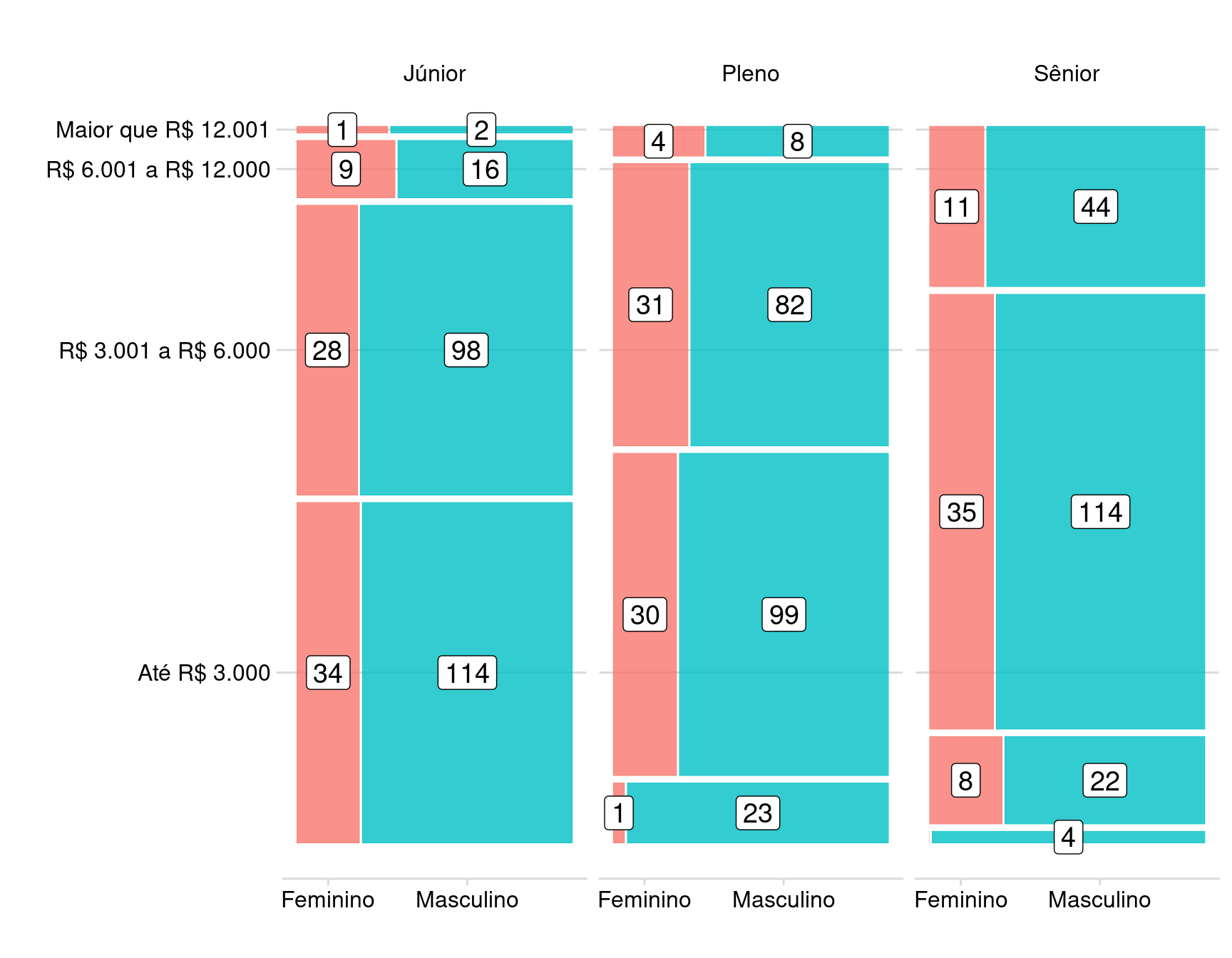
Percebemos que as categorias mais altas de Salário são inexistes para o gênero Feminino.
Modelo
Utilizei o modelo Cumulative Link Models for Ordinal Regression, pois os seguintes não encontravam:
Modelo Logístico tradicional são duas respostas
Modelo Multinomial são várias respostas mas sem ordemx
Modelo de Aprendizado de Máquina, não possui muitos registros para performar adequadamente
Para mais detalhes consulte a Vinheta CLM.
O modelo Aplicado será usado com a variável gênero sendo colocado como última
Resultados
Vamos Validar a Qualidade do Modelo pela Matrix de Confusão
Vamos Verificar A Performance do Modelo via Indicador Kappa e Acurácia
Vamos Explorar os resultados dos coeficientes para a variável Gênero.
Vamos Explorar os Principais coeficientes Que Explicam o Salário.
Matriz de Confusão
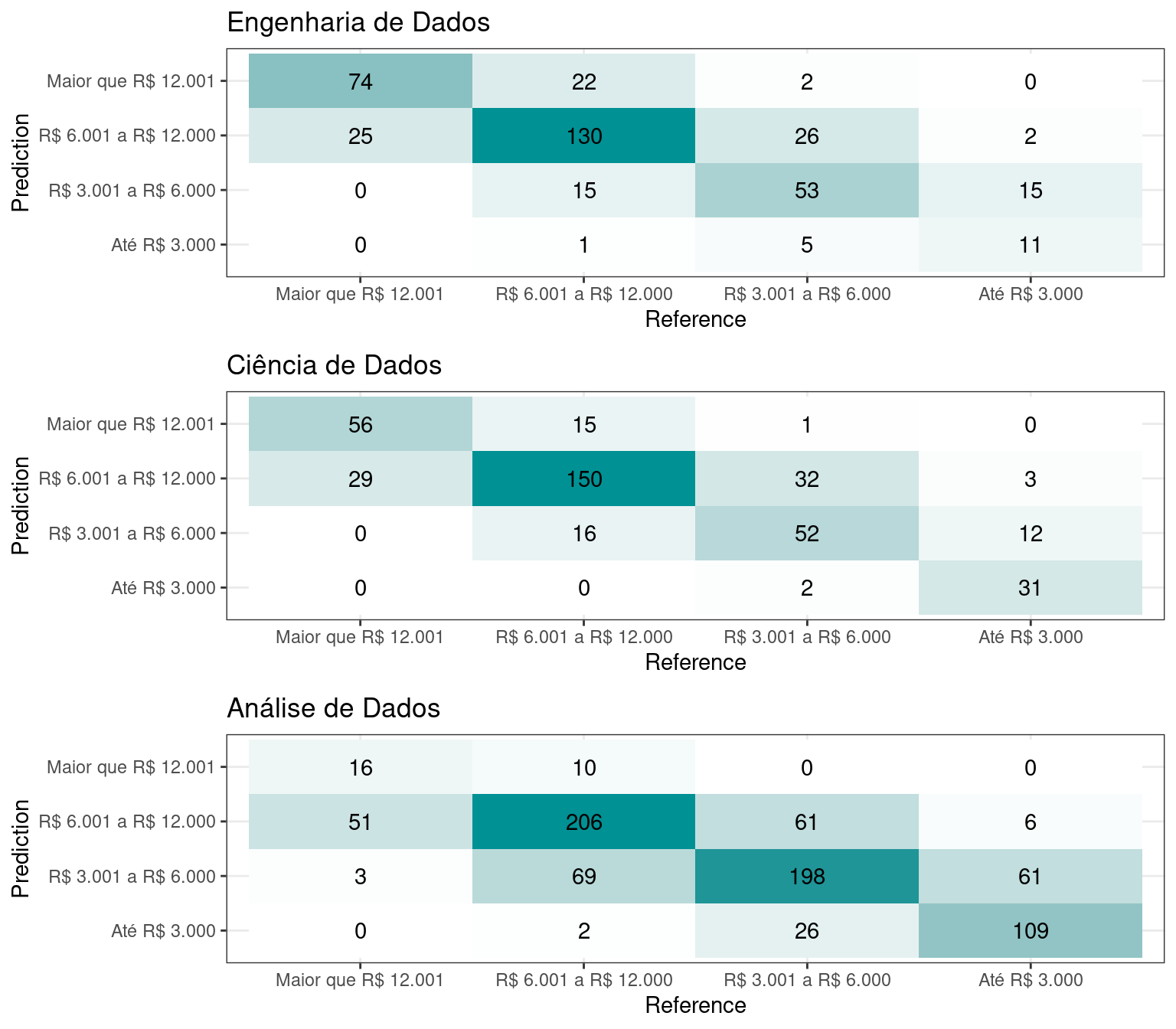
O resultado da Matrix de Confusão, mostra que há predomínio na diagonal principal. Ou seja as categorias preditas são correspondidos com a respectiva observado pela categoria
Performance
| p4_a_atuacao | Accuracy | Kappa |
|---|---|---|
| Engenharia de Dados | 0.7034121 | 0.5566163 |
| Ciência de Dados | 0.7243108 | 0.5854311 |
| Análise de Dados | 0.6466993 | 0.4814256 |
O resultado da performance é satisfatório, acurácia de 70%. O indicador de Kappa [0,40 |- 0,59] entre confirma uma concordância moderada dos resultados.
Coeficiente Gênero
| p4_a_atuacao | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| Engenharia de Dados | 1.061 | 0.343 | 0.174 | 0.862 | 0.540 | 2.079 |
| Ciência de Dados | 1.275 | 0.305 | 0.796 | 0.426 | 0.701 | 2.321 |
| Análise de Dados | 0.689 | 0.184 | -2.026 | 0.043 | 0.481 | 0.988 |
O resultado mostra que para engenharia de Ciência, o salário não tem relação com o gênero, pois o pvalue está acima de 0.05.
A profissão de analista mostra uma leve inclinação a ser caracterizado pelo gênero, repare nos valores de conf.low e conf.high
é o intervalo de confiança do estimate quase chega no 1.
Coeficientes Mais relevantes
Confira os 5 coeficientes mais relevantes para determinar o salário de cada profissão, cargo, experiencia, trabalho no exterior e ferramentas.
| term | estimate | p.value |
|---|---|---|
| Engenharia de Dados | ||
| p2_nd_cargoSênior | 123.125 | 0.000 |
| p2_a_qual_sua_situacao_atual_de_trabalho_ndexterior | 41.156 | 0.000 |
| p2_nd_cargoPleno | 10.872 | 0.000 |
| p2_i_quanto_tempo_de_experiencia_na_area_de_dados_voce_tem_ndDepois de 6 anos | 8.632 | 0.000 |
| p4_d_j_scala1 | 2.875 | 0.006 |
| Ciência de Dados | ||
| p2_nd_cargoSênior | 45.122 | 0.000 |
| p2_a_qual_sua_situacao_atual_de_trabalho_ndServidor Público | 15.273 | 0.000 |
| p2_nd_cargoPleno | 8.415 | 0.000 |
| p2_i_quanto_tempo_de_experiencia_na_area_de_dados_voce_tem_ndDepois de 6 anos | 5.285 | 0.003 |
| p2_i_quanto_tempo_de_experiencia_na_area_de_dados_voce_tem_ndde 4 a 5 anos | 4.204 | 0.004 |
| Analista de Dados | ||
| p2_nd_cargoSênior | 33.269 | 0.000 |
| p2_a_qual_sua_situacao_atual_de_trabalho_ndexterior | 15.626 | 0.000 |
| p2_nd_cargoPleno | 5.204 | 0.000 |
| p2_i_quanto_tempo_de_experiencia_na_area_de_dados_voce_tem_ndDepois de 6 anos | 4.668 | 0.000 |
| p2_a_qual_sua_situacao_atual_de_trabalho_ndServidor Público | 3.826 | 0.004 |
Conclusões
Os principais atributos para explicar o salário em dados são cargo e experiência , local de trabalho e as ferramentas. A variável gênero não explica o salário, em engenharia e ciencia. Na profissão de analista, repare que no gráfico de Mosaico, o analista aumenta sutilmente proporcional o feminino no cargo júnior. Sendo assim, considerado estatisticamente significativo a 0.05, aplicando um ponto de corte mais rigoroso como 0.01, não há efeito. O modelo foi validado e apresentou performances razoáveis.